 Платформа
Платформа Добавить публикацию
Добавить публикацию Реклама
Реклама Центр инноваций
Центр инноваций Партнеры
Партнеры hello@technovery.com
hello@technovery.com telegram
telegram

Каждый фотограф знает эту истину: когда дело доходит до камер и оборудования, все может стать масштабным и быстрым. Особенно в отделе объективов. Хотя беззеркальные камеры сначала рекламировались как более компактная и легкая альтернатива коренастым зеркалкам (и в некотором смысле они все еще придерживаются этого обещания), трудно игнорировать тот факт, что эти когда-то многообещающие легкие системы могут быстро увязнуть в стекле . И хотя линзы были частью фотографического процесса с самого начала, новаторские исследования группы ученых из Токийского технологического института могут привести к новым безлинзовым системам обработки изображений и, в конечном итоге, к безлинзовому будущему.

Проблемы безобъективной камеры
Концепция безлинзовой камеры не совсем нова. Однако до сих пор технология еще не давала пригодных для использования результатов, а вычислительное время, необходимое для рендеринга изображений, было слишком вялым для практического использования.
Текущая технология требует решения задачи выпуклой оптимизации, а итерационные вычисления (что означает, что может быть возвращено несколько результатов) делают этот процесс затяжным. Но предложение Tokyo Tech дает возможность значительно улучшить процесс.
«Глубокое обучение может помочь избежать ограничений декодирования на основе моделей, поскольку вместо этого оно может изучать модель и декодировать изображение с помощью неитеративного прямого процесса», — объяснила команда на Phys.org . «Существующие методы глубокого обучения для безлинзовой визуализации, в которых используется сверточная нейронная сеть (CNN), не могут создавать высококачественные изображения. Они неэффективны, потому что CNN обрабатывает изображение на основе взаимосвязей соседних «локальных» пикселей, тогда как безлинзовая оптика преобразует локальную информацию в сцене в перекрывающуюся «глобальную» информацию обо всех пикселях датчика изображения с помощью свойства, называемого «мультиплексирование». ‘”

Исследователи Tokyo Tech предлагают новую технологию
Команда Tokyo Tech предложила новый метод реконструкции изображений с использованием математического алгоритма. Аппаратное обеспечение состоит из маски и датчика изображения, при этом маска кодирует падающий свет (свет, падающий на объект), который затем отбрасывает узоры на датчик.
Глядя на эти узоры, человеческий глаз не смог бы расшифровать какую-либо полезную информацию — все отображается как непонятные пятна, похожие на след, оставленный, когда вы бросаете спагетти на стену или изображаете Джексона Поллока на холсте. Однако оптический алгоритм способен декодировать информацию, давая довольно точные результаты.
«Без ограничений объектива безлинзовая камера могла бы быть сверхминиатюрной, что позволило бы использовать новые приложения, которые выходят за рамки нашего воображения», — говорит профессор Масахиро Ямагути из Tokyo Tech.
Как это устроено
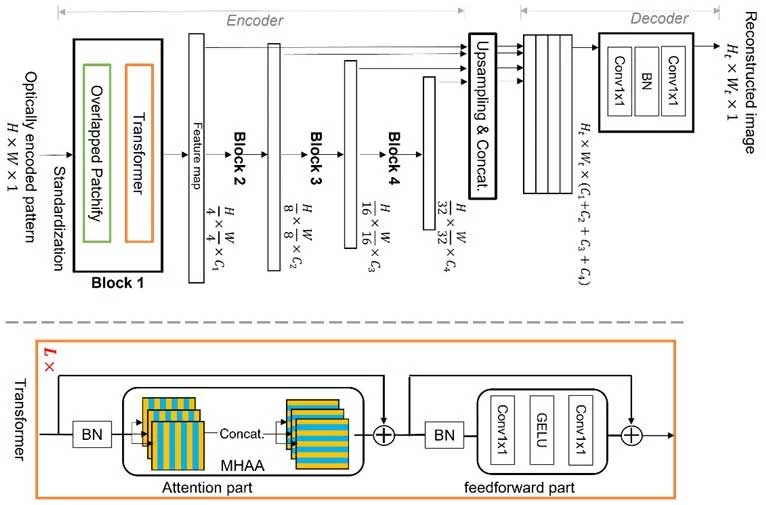
Команда впервые разработала технологию, которую они назвали Vision Transformer (ViT), которая может изучать особенности изображения в том, что они называют «иерархическим» способом, тем самым избегая традиционной обработки CNN. Это означает прямую реконструкцию без необходимости итерационных вычислений и уменьшение ошибок аппроксимации.
Там, где CNN полагалась на локальную информацию о пикселях, ViT может использовать глобальные функции изображения. Согласно экспериментам, процесс является жизнеспособным, и предлагаемая камера создает высококачественные изображения со временем обработки, которое позволит осуществлять захват в реальном времени.
«Конечная цель безобъективной камеры — быть миниатюрной, но мощной. Мы рады быть лидерами в этом новом направлении решений для обработки изображений и датчиков следующего поколения», — говорит ведущий автор исследования г-н Сюкси Пан из Tokyo Tech.
Бесплатная служба распространения новостей для научных организаций и стартапов
hello@technovery.com



