 Платформа
Платформа Добавить публикацию
Добавить публикацию Реклама
Реклама Центр инноваций
Центр инноваций Партнеры
Партнеры hello@technovery.com
hello@technovery.com telegram
telegram

Генеративно-состязательные сети (GAN), класс сред машинного обучения, которые могут генерировать новые тексты, изображения, видео и голосовые записи, оказались очень полезными для решения многочисленных реальных проблем. Например, GAN успешно использовались для создания наборов данных изображений для обучения других алгоритмов глубокого обучения, для создания видео или анимации для конкретных целей и для создания подходящих подписей к изображениям.
Исследователи из Лаборатории компьютерного зрения и биометрии ИИТ Аллахабада и Университета Виньяна в Индии недавно разработали новую модель на основе GAN, которая может генерировать сжатые изображения из текстовых описаний. Эта модель, представленная в статье, предварительно опубликованной на arXiv, может открыть интересные возможности для хранения изображений и обмена контентом между различными интеллектуальными устройствами.
«Идея T2CI GAN согласуется с темой «прямой обработки/аналитики данных в сжатом домене без полной распаковки», над которой мы работаем с 2012 года», — Мохаммед Джавед, один из ученых, проводивших исследование. «Однако идея в T2CI GAN немного отличается, так как здесь мы хотели создавать/извлекать изображения в сжатой форме с учетом текстовых описаний изображения».
В своих прошлых исследованиях Джавед и его коллеги использовали GAN и другие модели глубокого обучения для решения многочисленных задач, включая извлечение признаков из данных, сегментацию данных текста и изображения , обнаружение слов в больших текстовых отрывках и создание сжатых файлов JPEG. . Новая модель, которую они создали, основывается на этих предыдущих попытках решить вычислительную проблему, которая до сих пор редко исследовалась в литературе.
В то время как несколько других исследовательских групп использовали методы, основанные на глубоком обучении, для создания изображений на основе текстовых описаний, лишь немногие из этих методов создают изображения в их сжатой форме. Кроме того, большинство существующих методик, генерирующих сжатые изображения, подходят к задаче генерации изображения и его сжатия по отдельности, что увеличивает их вычислительную нагрузку и время обработки.
«T2CI-GAN — это модель, основанная на глубоком обучении, которая использует текстовые описания в качестве входных данных и создает визуальные изображения в сжатой форме», — пояснил Джавед. «Преимущество здесь заключается в том, что обычные методы создают визуальные изображения из текстовых описаний, и они дополнительно подвергают эти изображения сжатию для создания сжатых изображений. Наша модель, с другой стороны, может напрямую отображать / изучать текстовые описания и создавать сжатые изображения. .»
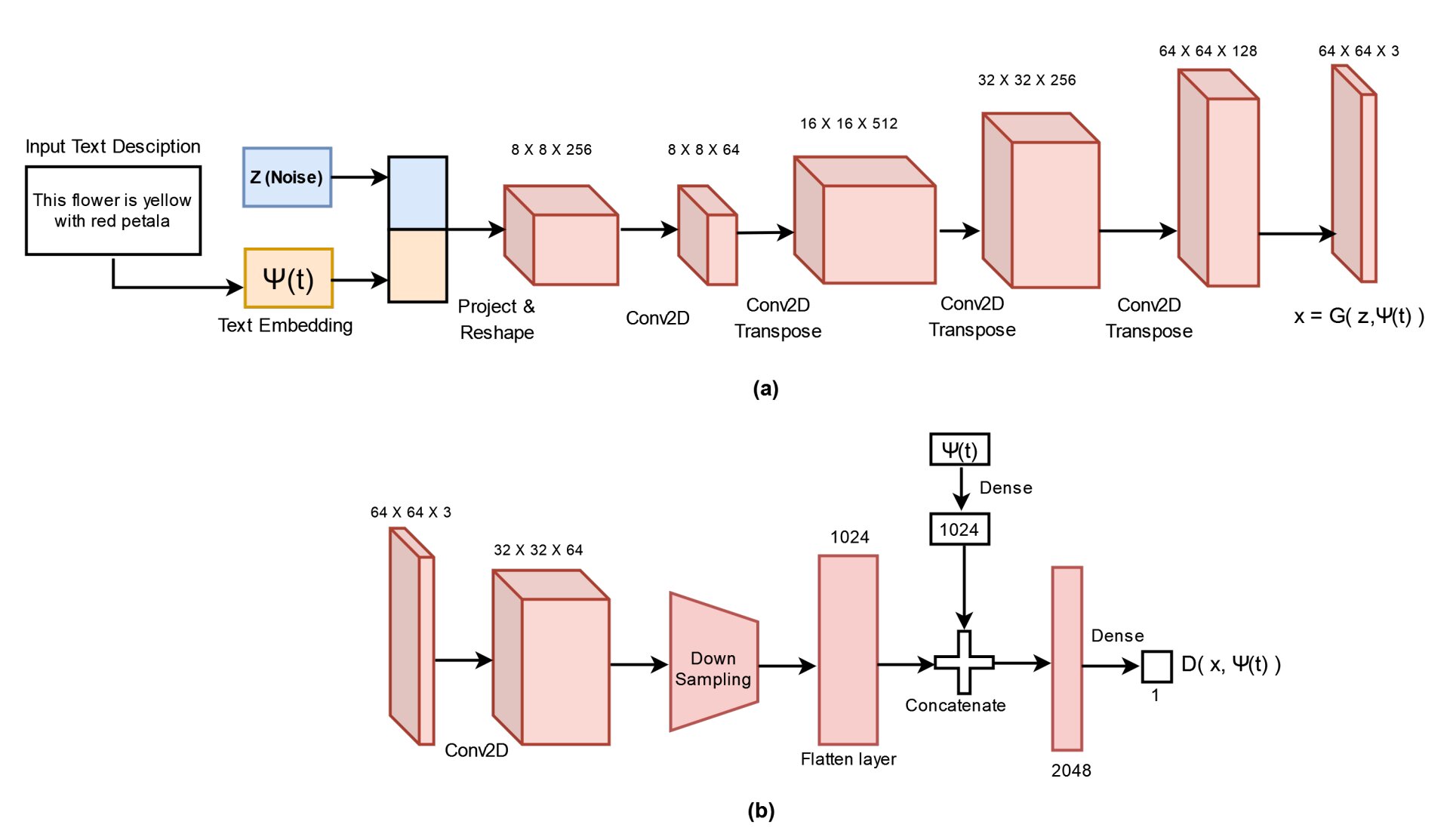
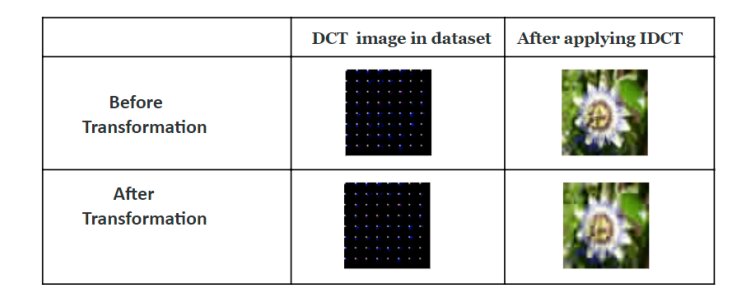
Джавед и его коллеги разработали две разные модели на основе GAN для создания сжатых изображений из текстовых описаний. Первая из этих моделей обучалась на наборе данных, содержащем сжатые изображения DCT (дискретное косинусное преобразование) в формате JPEG. После обучения эта модель смогла генерировать сжатые изображения на основе текстовых описаний.
С другой стороны, вторая модель исследователей на основе GAN была обучена на наборе изображений RGB. Эта модель научилась генерировать сжатые в формате JPEG DCT-представления изображений, которые конкретно выражают последовательность точек данных в виде математического уравнения.
«T2CI-GAN — это будущее, потому что мы знаем, что мир движется в направлении связи между машинами (роботами) и людьми с машинами», — сказал Джавед. «В таком сценарии машинам нужны только данные в сжатой форме, чтобы интерпретировать или понимать их. Например, представьте, что человек просит бота Alexa отправить ее детскую фотографию ее лучшему другу. Alexa поймет голосовое сообщение человека (текст описание) и попробуй поискать это фото, которое уже где-то хранится в сжатом виде, и отправить его прямо ее подруге».
Джавед и его коллеги оценили свою модель в серии тестов, используя известный набор данных Oxtford-102 Flower, который содержит несколько изображений цветов, разделенных на 102 типа цветов. Их результаты были очень многообещающими, поскольку их модель могла быстро и эффективно генерировать сжатые версии изображений в формате JPEG из набора данных цветов.
Модель T2CI-GAN можно использовать для улучшения автоматизированных систем поиска изображений, особенно когда исходные изображения предназначены для простого обмена со смартфонами или другими интеллектуальными устройствами. Кроме того, это может оказаться ценным инструментом для специалистов по СМИ и коммуникациям, помогая им извлекать более легкие версии определенных изображений для публикации на онлайн-платформах.
«В настоящее время модель T2CI GAN создает изображения только в сжатом формате JPEG», — добавил Джавед. «В нашей будущей работе мы хотели бы увидеть, сможем ли мы иметь общую модель, которая может создавать изображения в любой сжатой форме без каких-либо ограничений алгоритма сжатия».
Дополнительная информация: Булла Раджеш, Нандакишор Дуса, Мохаммед Джавед, Шив Рам Дубей, П. Нагабхушан, T2CI-GAN: преобразование текста в сжатое изображение с использованием генеративно-состязательной сети. arXiv:2210.03734v1 [cs.CV], arxiv.org/abs/2210.03734
Будьте в курсе в удобном формате, присоединяйтесь: TG-канал и ВК
Бесплатная служба распространения новостей для научных организаций и стартапов
hello@technovery.com



