 Платформа
Платформа Добавить публикацию
Добавить публикацию Реклама
Реклама Центр инноваций
Центр инноваций Партнеры
Партнеры hello@technovery.com
hello@technovery.com telegram
telegram

В прошлом году Институт интеллектуальных систем им. Макса Планка организовал соревнование Real Robot Challenge , в рамках которого академические лаборатории предложили решения проблемы изменения положения и ориентации куба с помощью недорогой роботизированной руки. Команды, участвовавшие в испытании, попросили решить серию задач по манипулированию объектами с разным уровнем сложности.
Чтобы решить одну из проблем, связанных с Real Robot Challenge, исследователи из Института вектора Университета Торонто, ETH Zurich и MPI Tubingen разработали систему, которая позволяет роботам приобретать сложные навыки ловких манипуляций, эффективно передавая эти навыки из моделирования в настоящего робота . Эта система, представленная в статье, предварительно опубликованной на arXiv, достигла замечательного успеха в 83%, позволив удаленной системе TriFinger, предложенной организаторами задач, выполнять сложные задачи, требующие ловких манипуляций.
«Наша цель состояла в том, чтобы использовать методы, основанные на обучении, для решения проблемы, представленной в прошлогоднем испытании Real Robot Challenge, с меньшими затратами», — сказал TechXplore один из исследователей, проводивший исследование. «Мы особенно вдохновлены предыдущей работой над системой OpenAI Dactyl , которая показала, что можно использовать бесплатное обучение с подкреплением в сочетании с рандомизацией домена для решения сложных задач манипуляции».
По сути, Гарг и его коллеги хотели продемонстрировать, что они могут решать задачи ловких манипуляций с помощью роботизированной системы Trifinger, перенося результаты, достигнутые в моделировании, в реальный мир, используя меньше ресурсов, чем те, которые использовались в предыдущих исследованиях. Для этого они создали метод глубокого обучения, который может планировать будущие действия на основе наблюдений робота.

«Процесс, которому мы следовали, состоит из четырех основных шагов: настройка среды в физическом моделировании, выбор правильной параметризации для спецификации задачи, изучение надежной политики и внедрение нашего подхода на реальном роботе», — пояснил Гарг.
Смоделированная среда была создана с помощью недавно выпущенного NVIDIA Isaac Gym Simulator. Этот симулятор позволяет добиться очень реалистичного моделирования, используя мощь графических процессоров NVIDIA. Используя платформу Isaac Gym, Гарг и его коллеги смогли значительно сократить объем вычислений, необходимых для перевода навыков ловких манипуляций из моделирования в реальные настройки, снизив требования к своей системе с кластера с сотнями процессоров и нескольких графических процессоров на один графический процессор.
«Обучение с подкреплением требует, чтобы мы использовали представления переменных в нашей проблеме, соответствующие решению задачи», — сказал Гарг. «Задача Real Robot требовала, чтобы конкуренты откладывали кубики как в положении, так и в ориентации. Это сделало задачу значительно более сложной, чем предыдущие попытки, поскольку обученный контроллер нейронной сети должен был иметь возможность сочетать эти две цели».
Чтобы решить проблему манипулирования объектами, возникшую в задаче «Настоящий робот», Гарг и его коллеги решили использовать «представление ключевых точек», способ представления объектов путем сосредоточения внимания на основных «точках интереса» на изображении. Это точки, которые остаются неизменными независимо от размера изображения, поворота, искажения или других вариаций.
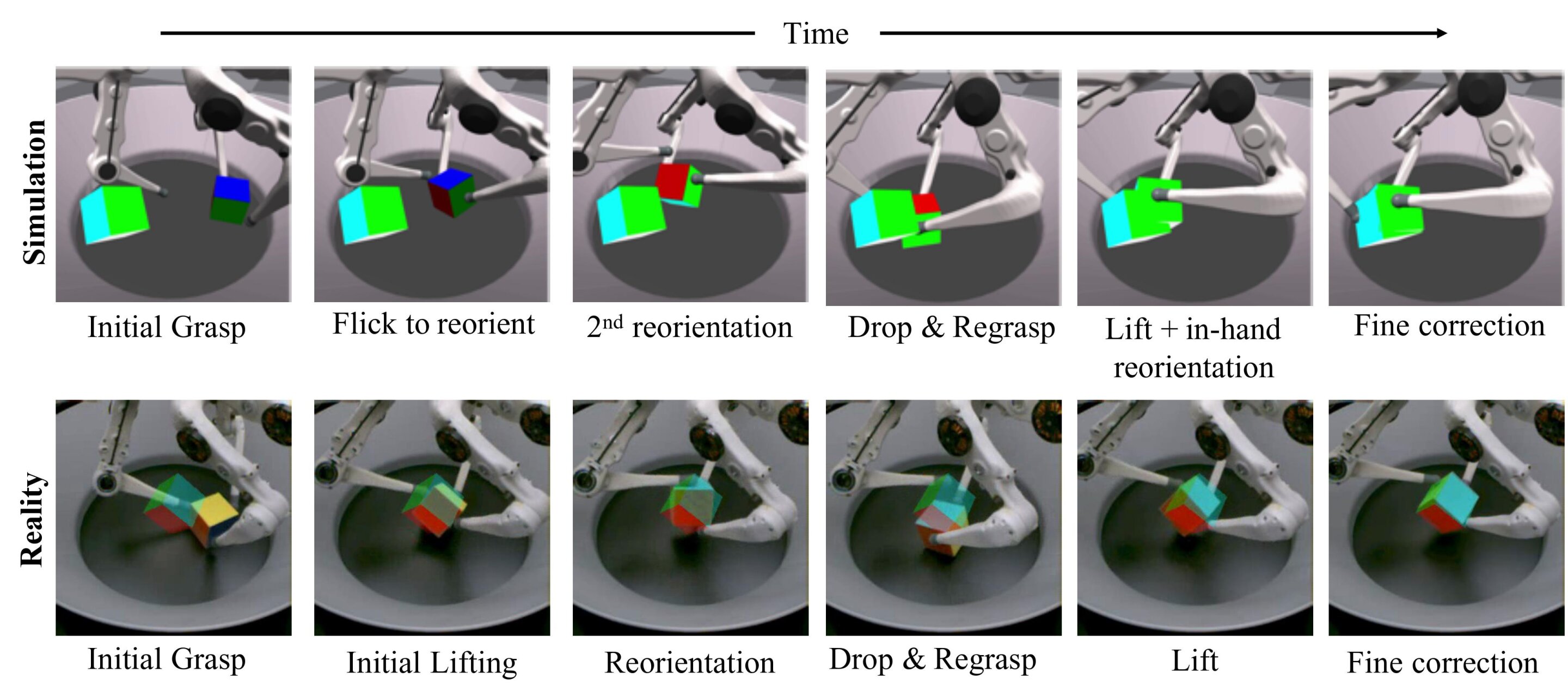
В своем исследовании ученые использовали ключевые точки для представления позы куба, которым робот должен был манипулировать, в данных изображения, передаваемых в их нейронную сеть. Они также использовали их для расчета так называемой функции вознаграждения, которая в конечном итоге может позволить алгоритмам обучения с подкреплением улучшать свою производительность с течением времени.
«Наконец, мы добавили рандомизацию в среду», — сказал Гарг. «Параметры включают рандомизацию входных данных в сеть, предпринимаемые действия, а также различные параметры среды, такие как трение куба и добавление к нему случайных сил. В результате контроллер нейронной сети вынужден демонстрировать поведение, которое устойчив к целому ряду параметров окружающей среды «.
Исследователи натренировали свою модель обучения с подкреплением в симулированной среде, которую они создали с помощью Isaac Gym, в течение одного дня. При моделировании алгоритм был представлен 16000 смоделированных роботов, производящих ~ 50 000 шагов в секунду данных, которые затем использовались для обучения сети.
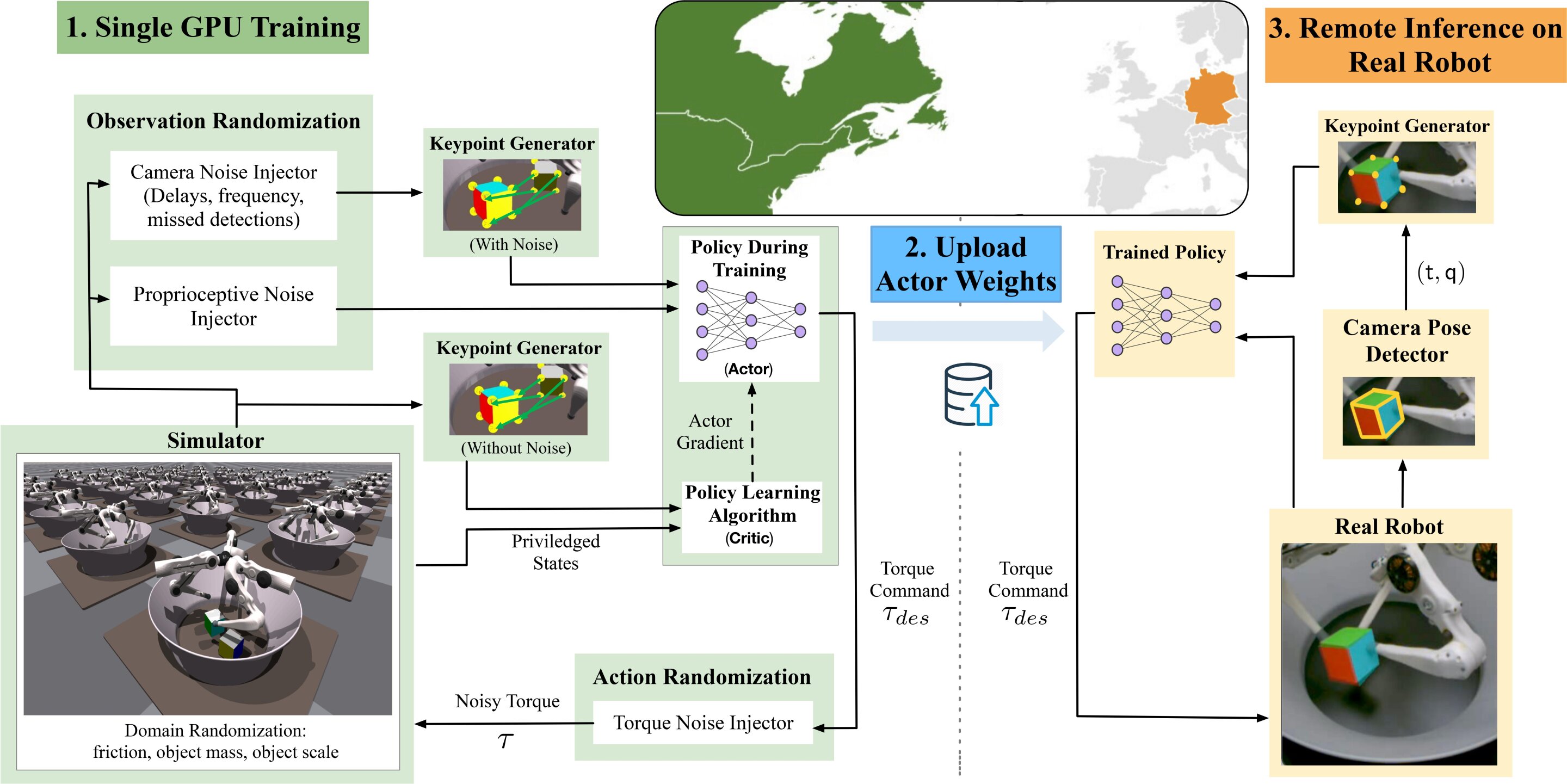
Гарг и его коллеги в конечном итоге смогли эффективно передать результаты, достигнутые их алгоритмом глубокого обучения с подкреплением в симуляциях, на реальных роботов с гораздо меньшей вычислительной мощностью, чем требовалось другим командам. Кроме того, они продемонстрировали эффективную интеграцию инструментов высокопараллельного моделирования с современными методами глубокого обучения с подкреплением для эффективного решения сложных задач ловких манипуляций.
Дополнительная информация: Артур Оллшир и др., «Передача ловких манипуляций из симуляции графического процессора на удаленный реальный трипальчик». arXiv: 2108.09779v1 [cs.RO], arxiv.org/abs/2108.09779
Иллюстрации: Allshire et al.
Будьте в курсе в удобном формате, присоединяйтесь: TG-канал и ВК



