 Платформа
Платформа Добавить публикацию
Добавить публикацию Реклама
Реклама Центр инноваций
Центр инноваций Партнеры
Партнеры hello@technovery.com
hello@technovery.com telegram
telegram

Недавнее появление генеративных моделей, вычислительных инструментов, которые могут генерировать новые тексты или изображения на основе данных, на которых они обучаются, открыло интересные новые возможности для творческих отраслей. Например, они позволяют художникам и создателям цифрового контента легко создавать реалистичный медиаконтент, объединяющий элементы изображений или видео.
Вдохновленные этими недавними достижениями, исследователи из Стэнфордского университета, Калифорнийского университета в Беркли и Adobe Research разработали новую модель, которая может реалистично вставлять конкретных людей в различные сцены, например, показывая, как они тренируются в тренажерном зале, наблюдают закат на пляже и так далее.
Предлагаемая ими архитектура, основанная на классе генеративных моделей, известных как модели распространения, была представлена в документе, предварительно опубликованном на сервере arXiv и предназначенном для представления на конференции по компьютерному зрению и распознаванию образов (CVPR) 2023 в Ванкувере. в этом июне.
«Визуальные системы по своей природе обладают способностью делать выводы о потенциальных действиях или взаимодействиях, которые позволяет окружающая среда или сцена, концепция, известная как «возможности», — сказал Tech Xplore Сумит Кулал, один из участников, проводивших исследование.
«Это было предметом обширных исследований в области зрения, психологии и когнитивных наук. Вычислительные модели восприятия аффорданса, разработанные за последние два десятилетия, часто были ограничены из-за ограничений, присущих их методологиям и наборам данных. Однако впечатляющий реализм продемонстрировал с помощью крупномасштабных генеративных моделей показал многообещающий путь для прогресса. С учетом этих идей мы стремились создать модель, которая могла бы явно выявлять эти возможности».
Основная цель исследования Кулала и его коллег состояла в том, чтобы применить генеративные модели к задаче восприятия аффорданса в надежде на достижение более надежных и реалистичных результатов. В своей недавней статье они специально сосредоточились на проблеме реалистичного включения человека в данную сцену.

«Наши входные данные включают изображение человека и изображение сцены с обозначенной областью, а на выходе — реалистичное изображение сцены, которое теперь включает человека», — пояснил Кулал. «Наша крупномасштабная генеративная модель , обученная на наборе данных, состоящем из миллионов видео, предлагает большее обобщение для новых сцен и людей. Кроме того, наша модель демонстрирует ряд интригующих дополнительных возможностей, таких как галлюцинации человека и виртуальная примерка».
Кулал и его коллеги обучили диффузионную модель , тип генеративной модели, которая может превратить «шум» в желаемое изображение, используя подход к обучению с самоконтролем. Модели распространения, по сути, работают, «уничтожая» данные, на которых они обучаются, добавляя к ним «шум», а затем восстанавливая некоторые исходные данные, обращая этот процесс.
Во время обучения модель, созданная исследователями, получала видеоролики, показывающие движение человека в заданной сцене, и она случайным образом выбирала два кадра из каждого из этих видеороликов. Люди в первом кадре замаскированы, а это означает, что область пикселей вокруг человека затенена.
Затем модель пытается реконструировать людей в этом замаскированном кадре, используя тех же людей без маски во втором кадре в качестве условного сигнала. Таким образом, со временем модель может научиться реалистично воспроизводить то, как выглядели бы люди, если бы они были помещены в определенные сцены.
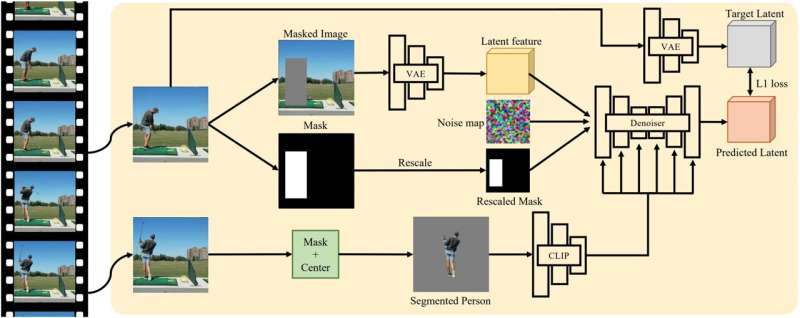
«Наш метод заставляет модель выводить возможную позу из контекста сцены, изменять позу человека и гармонизировать вставку», — сказал Кулал. «Ключевым компонентом этого подхода является наш набор данных, состоящий из миллионов видеороликов с участием людей. Благодаря своему масштабу наша модель, похожая по архитектуре на модель стабильной диффузии, исключительно хорошо обобщает различные входные данные».
Исследователи оценили свою генеративную модель в серии предварительных тестов, в ходе которых они скармливали ей новые изображения людей и сцен, а затем наблюдали, насколько хорошо она поместила этих людей в сцены. Они обнаружили, что модель работала на удивление хорошо, создавая отредактированные изображения, которые выглядели вполне реалистично. Возможности, предсказываемые их моделью, лучше и работают в более разнообразных условиях, чем те, которые были созданы негенеративными моделями, представленными в прошлом.
В будущем модель, разработанная Кулалом и его коллегами, может быть интегрирована в ряд творческих программных инструментов для расширения их функций редактирования изображений, что в конечном итоге поддержит работу художников и создателей медиа. Ее также можно добавить в приложения для смартфонов для редактирования фотографий, что позволит пользователям легко и реалистично вставлять человека в фотографии.
Дополнительная информация: Сумит Кулал и др. «Поставить людей на свои места: введение человека в сцену с учетом возможностей», arXiv (2023). DOI: 10.48550/arxiv.2304.14406
Будьте в курсе в удобном формате, присоединяйтесь: TG-канал и ВК
Бесплатная служба распространения новостей для научных организаций и стартапов
hello@technovery.com



